Step1: 爬蟲爬起來!
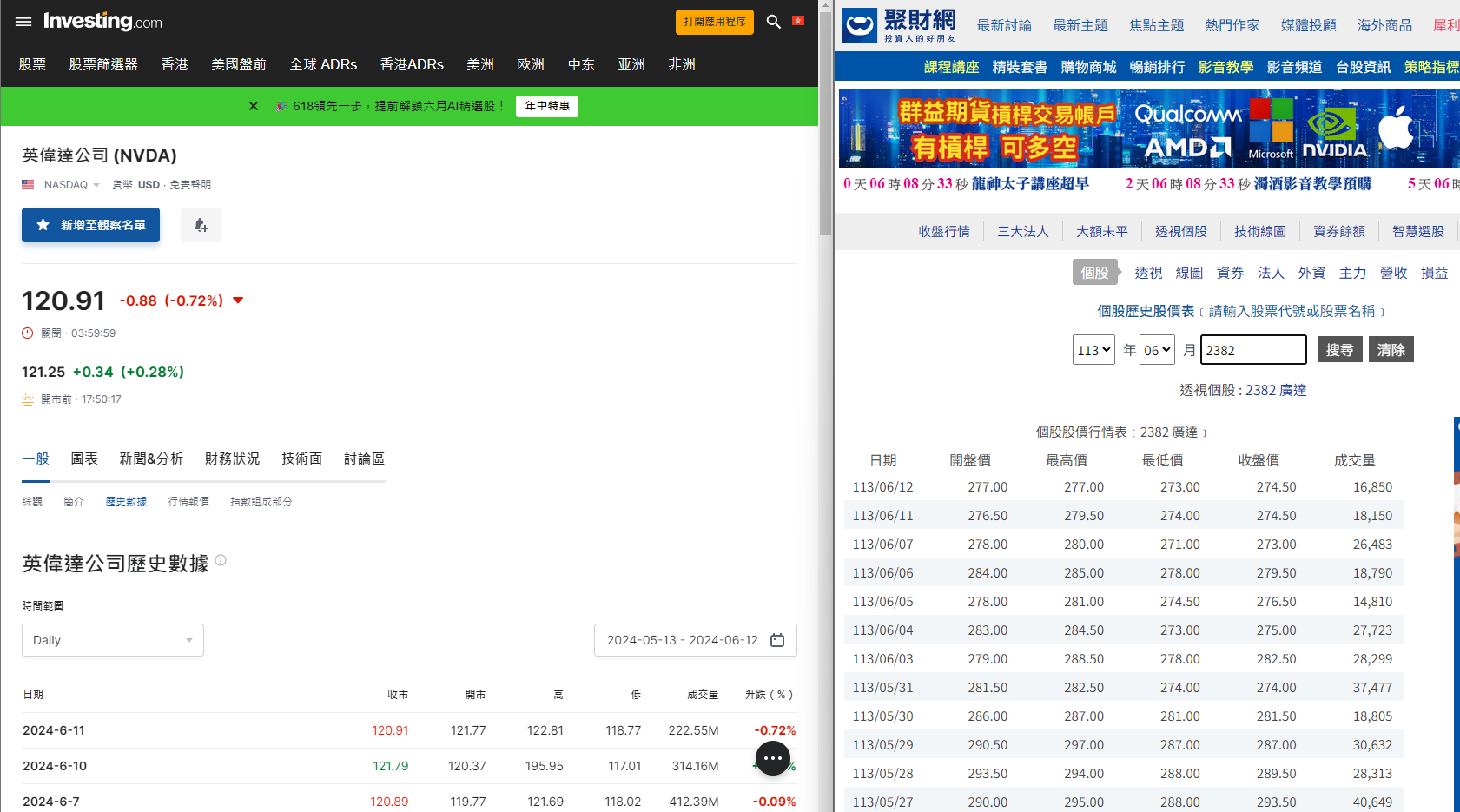 NVIDIAQUANTA
NVIDIAQUANTAStep2:對表格做爬蟲
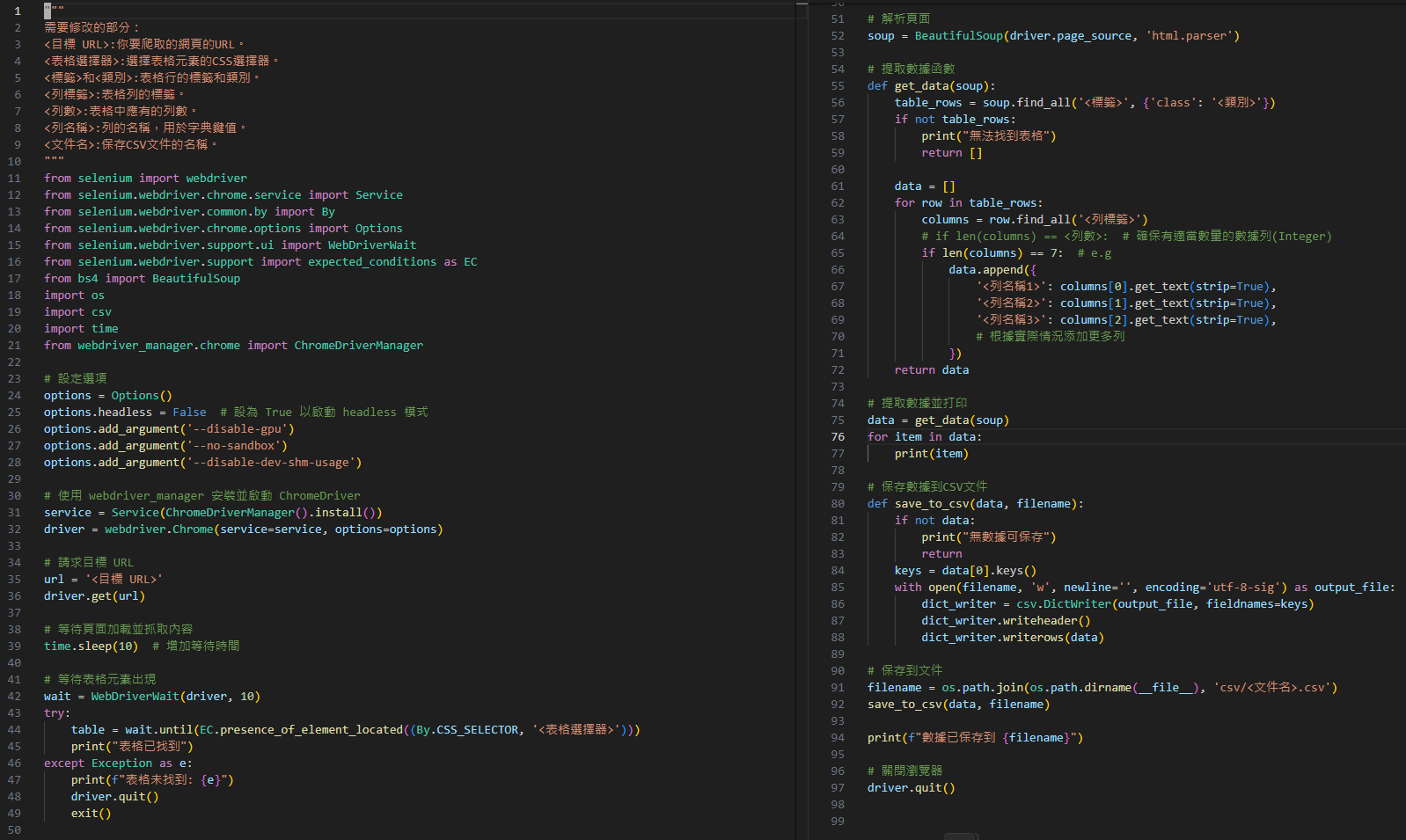
"""
需要修改的部分:
<目標 url>:你要爬取的網頁的URL。
<表格選擇器>:選擇表格元素的CSS選擇器。
<標籤>和<類別>:表格行的標籤和類別。
<列標籤>:表格列的標籤。
<列數>:表格中應有的列數。
<列名稱>:列的名稱,用於字典鍵值。
<文件名>:保存CSV文件的名稱。
"""
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from bs4 import BeautifulSoup
import os
import csv
import time
from webdriver_manager.chrome import ChromeDriverManager
# 設定選項
options = Options()
options.headless = False # 設為 True 以啟動 headless 模式
options.add_argument('--disable-gpu')
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# 使用 webdriver_manager 安裝並啟動 ChromeDriver
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
# 請求目標 URL
url = '<目標 url>'
driver.get(url)
# 等待頁面加載並抓取內容
time.sleep(10) # 增加等待時間
# 等待表格元素出現
wait = WebDriverWait(driver, 10)
try:
table = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, '<表格選擇器>')))
print("表格已找到")
except Exception as e:
print(f"表格未找到: {e}")
driver.quit()
exit()
# 解析頁面
soup = BeautifulSoup(driver.page_source, 'html.parser')
# 提取數據函數
def get_data(soup):
table_rows = soup.find_all('<標籤>', {'class': '<類別>'})
if not table_rows:
print("無法找到表格")
return []
data = []
for row in table_rows:
columns = row.find_all('<列標籤>')
# if len(columns) == <列數>: # 確保有適當數量的數據列(Integer)
if len(columns) == 7: # e.g
data.append({
'<列名稱1>': columns[0].get_text(strip=True),
'<列名稱2>': columns[1].get_text(strip=True),
'<列名稱3>': columns[2].get_text(strip=True),
# 根據實際情況添加更多列
})
return data
# 提取數據並打印
data = get_data(soup)
for item in data:
print(item)
# 保存數據到CSV文件
def save_to_csv(data, filename):
if not data:
print("無數據可保存")
return
keys = data[0].keys()
with open(filename, 'w', newline='', encoding='utf-8-sig') as output_file:
dict_writer = csv.DictWriter(output_file, fieldnames=keys)
dict_writer.writeheader()
dict_writer.writerows(data)
# 保存到文件
filename = os.path.join(os.path.dirname(__file__), 'csv/<文件名>.csv')
save_to_csv(data, filename)
print(f"數據已保存到 {filename}")
# 關閉瀏覽器
driver.quit()
Step3: 各模組統計分析
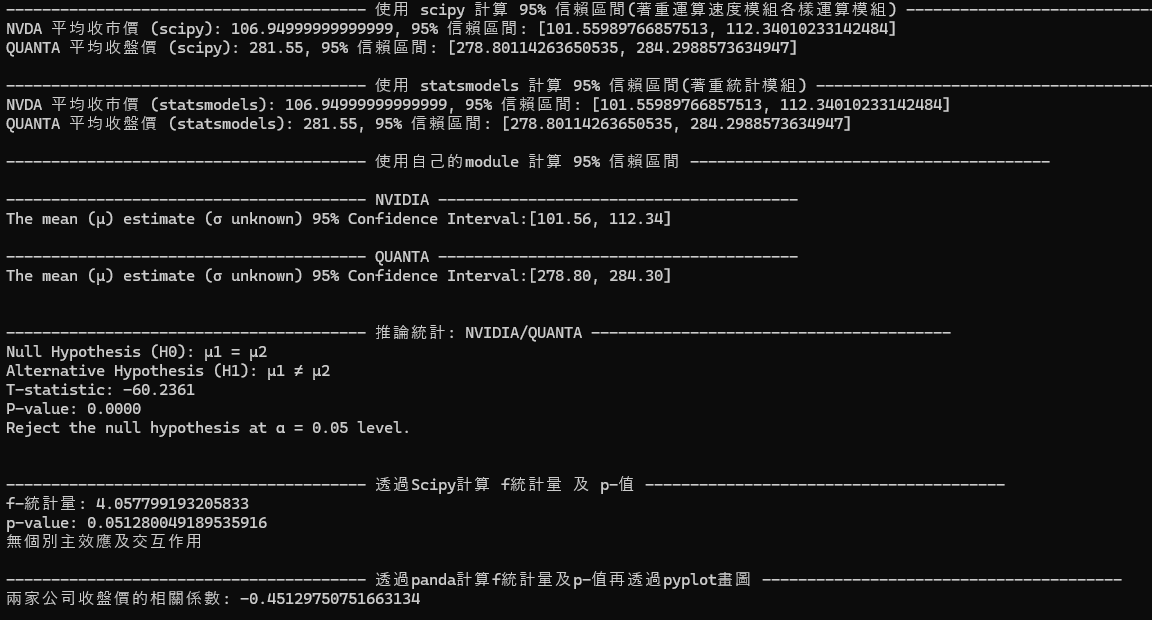
NVIDIA(英偉達)
versus
QUANTA(廣達)
結論
對於 NVIDIA 和 QUANTA 的平均股價進行了統計分析,並獲得了以下結果:
- NVIDIA 六月份的平均股價之 95% 信賴區間為 [101.56, 112.34]。
- QUANTA 六月份的平均股價之 95% 信賴區間為 [278.80, 284.30]。
進一步檢驗了 NVIDIA 和 QUANTA 之間的平均股價是否存在顯著差異。檢驗結果如下:
- 虛無(零)假設 (H0):μ1 = μ2
- 對立假設 (H1):μ1 ≠ μ2
- T 統計量:-60.2361
- P 值:0.0000
- 在α = 0.05下拒絕虛無假設
這意味著我們有足夠的證據認為 NVIDIA 和 QUANTA 的平均股價存在顯著差異。
總結
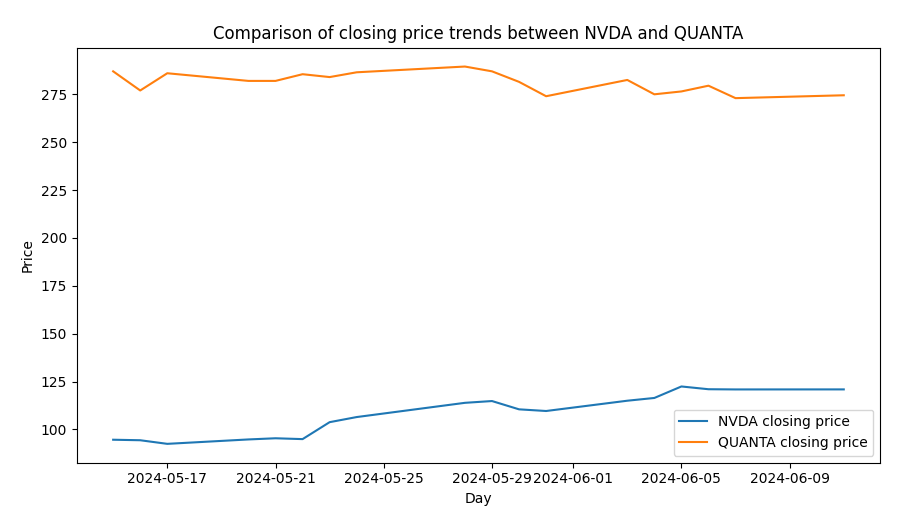
通過這次分析,我們發現 NVIDIA 和 QUANTA 的平均股價在統計上有顯著不同。股價漲動因素複雜,人性、環境、景氣...等諸多因素影響,兩公司之間並不會顯著關聯。